To continue where our last article left off, we'll be showing you how to use npm to download and use libraries in your Node.js applications. Open source libraries will help you write less code and be more productive. The npm ecosystem is diverse and has many thousands of useful libraries that you can use absolutely free of charge!
We'll be covering how npm is used, show some examples of importing express from npm and how to utilize it for running a custom HTTP server.
Installation
npm is actually distributed with Node.js as part of the base installation, and this means if you have Node.js installed then you should already have npm installed. If you don't have Node.js installed, you can get it on their website.
Basic npm Usage
npm's help prompt can be a bit overwhelming, so we're going to go over some of the most important commands you need to know in this article.
npm init
npm init can be used to set up a new npm package. This is the first step in setting up the structure for your Node.js application. An interactive prompt will ask you a few basic questions and generate a package.json file.
The resulting package.json file will look similar to this:
{
"name": "lets-build-a-web-app-with-npm-and-express",
"version": "1.0.0",
"description": "This is an example description!",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"example",
"express"
],
"author": "Walter Kuppens",
"license": "MIT"
}
Everything specified in the prompt was added into package.json, and not much else. Our file won't stay like this for long though as we will be installing a dependency. Dependencies and their versions are tracked in this file.
npm install
We'll be building a simple express application, so we want to install the express package from npm. This can be done by running npm install express in the project directory. When this completes, you'll notice a new directory called node_modules and a new file called package-lock.json.
node_modules contains the code for your dependencies. Since we installed express, the source code for it and all of its dependencies will be in this folder. Looking inside of the folder, you'll see that each dependency is organized in their own directories.
package-lock.json keeps track of the exact versions of the dependencies that were installed. This file is expecially useful as it can allow deployments of your application to be guaranteed to install the same versions of dependencies you installed during development. package.json uses semvar to track versions instead of exact version numbers, so subsequent setups of your application may have slightly varying versions of dependencies. Semvar has syntax that allows for finer control over what versions of dependencies are acceptable for installation. You can find out more about semvar in the npm documentation.
npm uninstall
npm uninstall simply uninstalls a package in its entirety. If you changed your mind on installing express for any reason, you can remove it by simply running npm uninstall express.
Let's Make an Express App
Let's start with a basic hello world program using express and move forward from there.
const express = require('express');
const app = express();
const port = 3000;
app.get('/', (req, res) => {
res.send('Hello Express!');
});
app.listen(port, () => {
console.log(`Listening on http://localhost:${port}`);
});
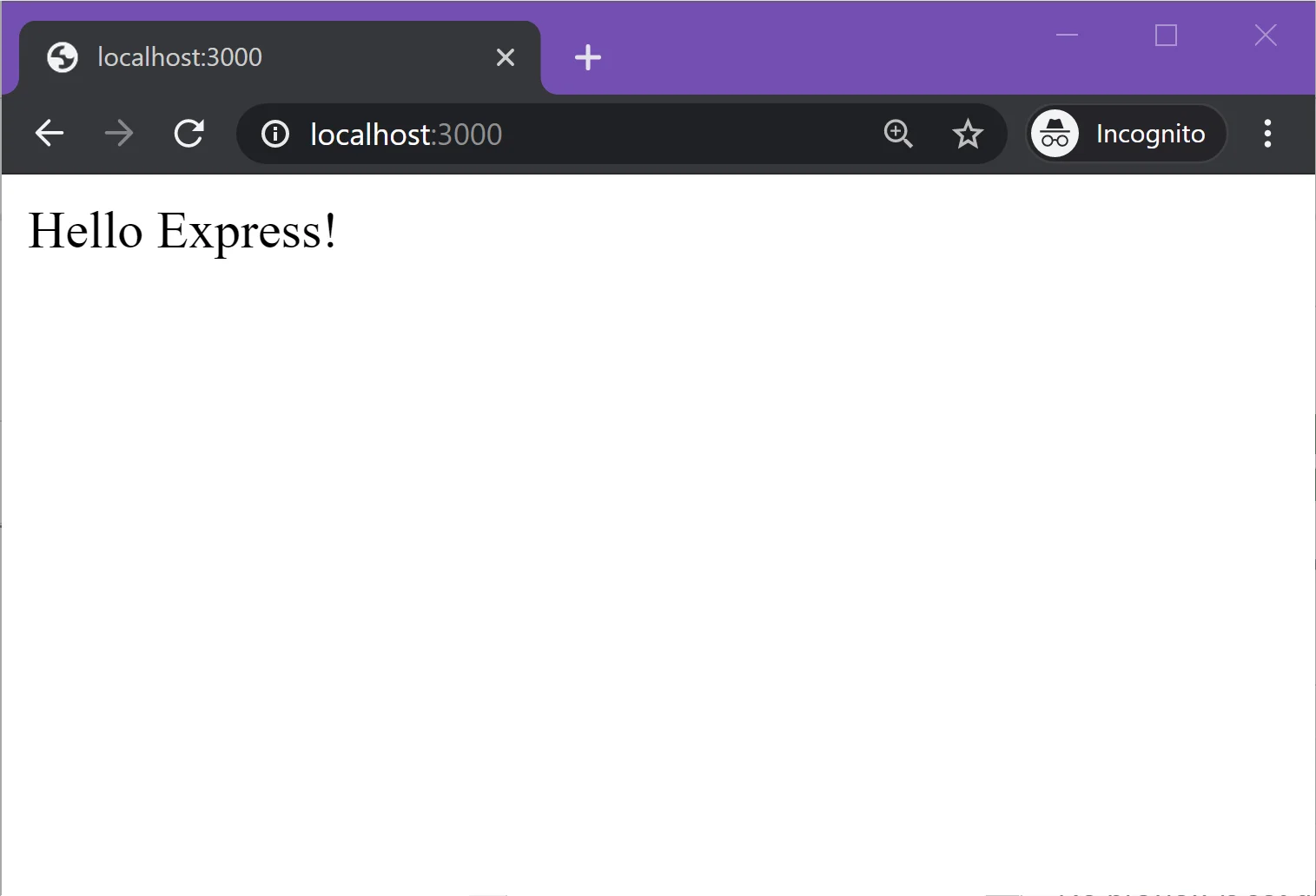
Save the above code in index.js and execute it using node index.js. This program will start a working HTTP server that listens on port 3000. We import express by using require('express') at the top of the file, and by calling the express() function it exports to get an application object. We can set up our routes and other configurations on the application object by calling its methods.
This example program will return a plain text response of "Hello Express!" when the root of the site is accessed. Any other routes will result in a standard 404 error. Try opening http://localhost:3000 in your browser while the server is running!
You could also set response codes and return JSON without much additional code. Let's add a route for GET /headers that returns the request HTTP headers as JSON.
...
// Configure the formatter to use 2 spaces for indentation. This is optional.
app.set('json spaces', 2);
// Let's return some JSON!
app.get('/headers', (req, res) => {
res.status(200).json(req.headers);
});
app.listen(port, () => {
console.log(`Listening on http://localhost:${port}`);
});
If you add that new code and restart the server, you should get the following at http://localhost:3000/headers:
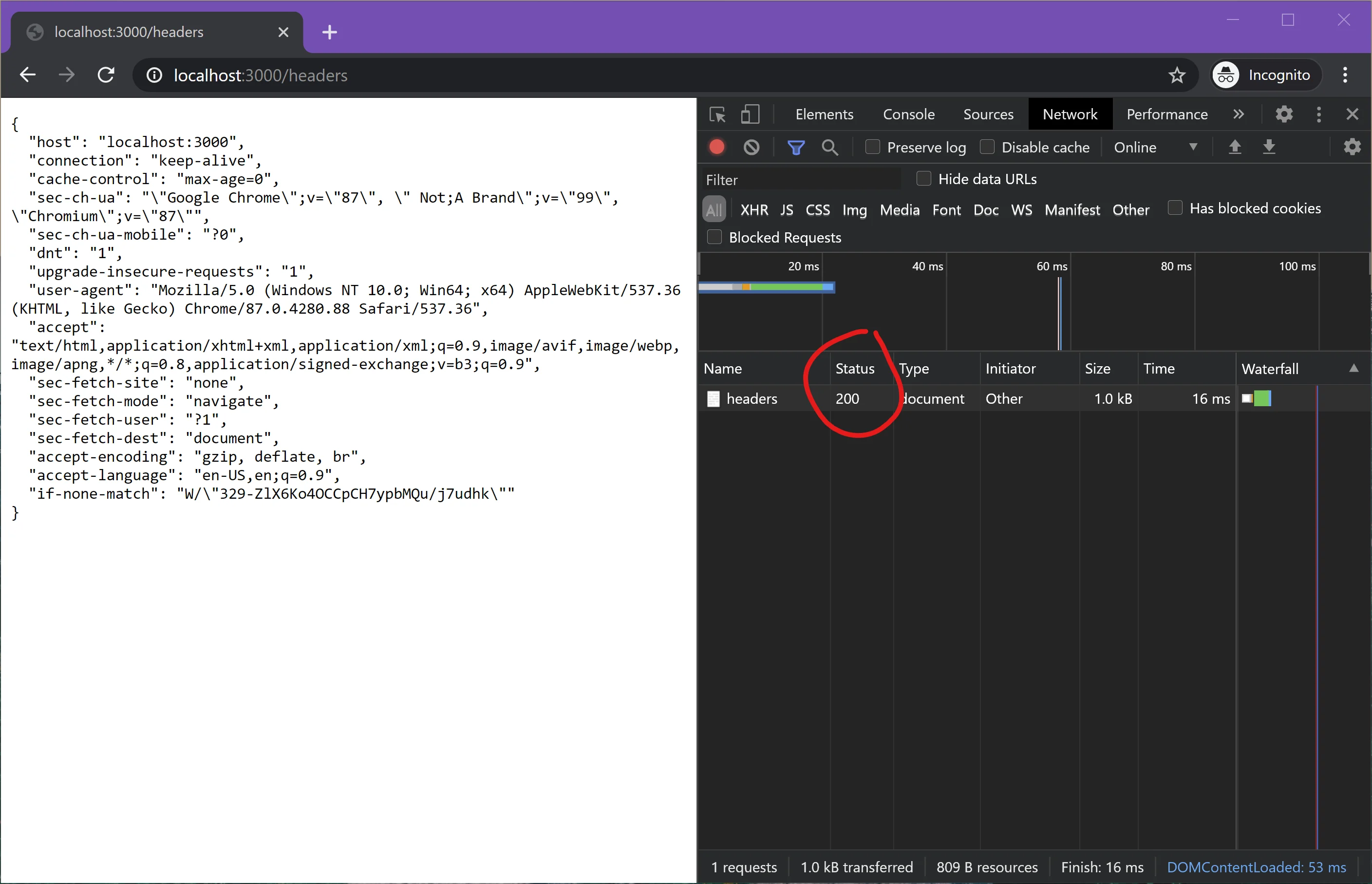
The response came back as formatted JSON and with our requested status code.
req and res
req and res are objects that are passed into each route handler. req contains HTTP request details from the client such as headers, cookies, data, urls, etc. The router also uses this object to determine which route handlers to call. A full list of parameters in the req object can be found here.
The res object contains information that we wish to pass back to the client. When we first start handling the HTTP request, this object won't have much in it. If want to change the status code or send some JSON data back to the client, we need to do it through res. Changes can be made by calling methods in res such as but not limited to, status(), cookie(), append(), redirect(), json() and send(). These methods can be chained together as they all return the res object they belong to.
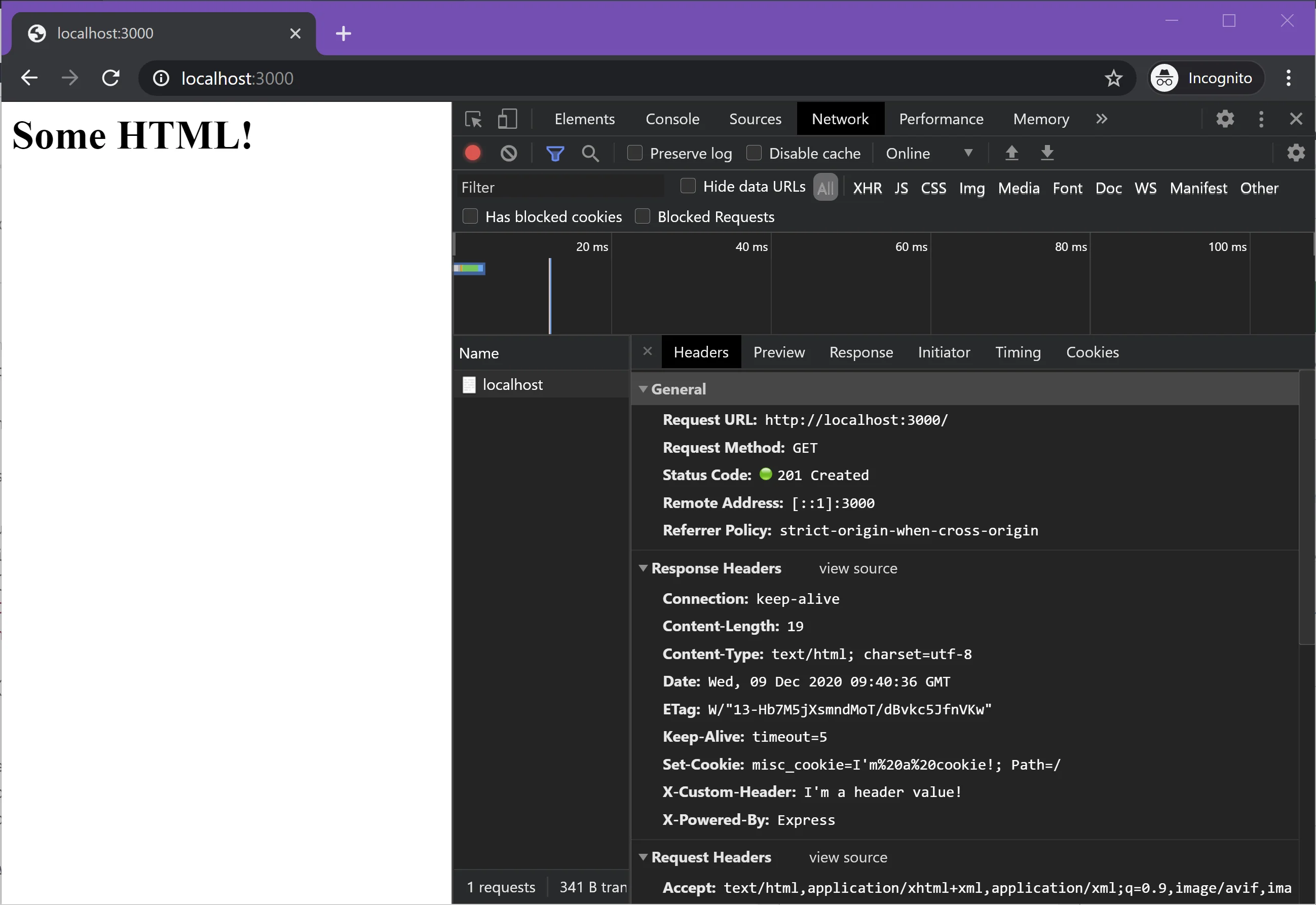
Let's change our route to return some HTML instead:
res
.status(201) // 201 = Created
.cookie('misc_cookie', "I'm a cookie!")
.set({
'X-Custom-Header': "I'm a header value!",
'Content-Type': 'text/html',
})
.send('<h1>Some HTML!</h1>');
Try accessing the route with your browser to see the HTML return. You can use your browser's developer tools to verify the response headers and status code got set properly as well!
Keep in mind that some of these methods will cause express to send a response back to the client when you call them, and you can only do this once. For example, the redirect(), json() and send() methods do this and should always be called against res last.
A full list of parameters and methods in the res object can be found here.
Conclusion
Package managers like npm can be a helpful tool for getting your projects up and running with as little code as possible. The JavaScript ecosystem has thousands of useful libraries at your disposal, and utilizing open source code can improve your productivity. We hope this was a helpful introduction to npm! Next we'll be looking at concurrency within Node.js, and async / await. Concurrency is one of Node's strengths when compared with other languages. Stay tuned!




